
Deep Dive: Fehlersuche und Behebung
Juniper hat sich mit seinem einheitlichen Betriebssystem Junos OS und einem umfangreichen Portfolio mit physischen und virtuellen Netzwerk- und Sicherheitsprodukten zu einem wichtigen Akteur auf dem globalen Markt entwickelt.
#Network as a Service #Deep Dive #Juniper Networks
Laut Wikipedia ist Juniper
- der drittgrösste Marktanteilseigner bei Routern und Switches, die von ISPs verwendet werden.
- der viertgrösste Marktanteilseigner für Edge-Router und der zweitgrösste Marktanteilseigner für Core-Router mit 25% des Core-Marktes.
- der zweitgrösste Marktanteilseigner bei Firewall-Produkten, mit einem Anteil von 24,8% am Firewall-Markt.
- der zweitgrösste Marktteilnehmer hinter Cisco bei Sicherheitsanwendungen für Rechenzentren.
- Im Bereich WLAN, in dem das Unternehmen früher einen eher marginalen Marktanteil hatte, durch die Übernahme von Mist Systems, einem Visionär im Bereich WLAN, auf einem expansiven Kurs. Gemäss Gartner ist Juniper in diesem Bereich sogar der Leader des Quadranten.
Deshalb sind die Produkte von Juniper in Hunderttausenden von Unternehmen auf der ganzen Welt im Einsatz, um deren Netzwerkbetrieb zuverlässig, sicher und flexibel zu gestalten.
Aber was ist zu tun, wenn Ihr Junos-Gerät unerwartete oder unerklärbare Probleme aufweist? Keine Panik! UMB als Juniper-Partner und der JTAC (Juniper Technical Assistance Center) ist für Sie da, um Sie zu unterstützen. Wenn Sie aber keinen Supportvertrag haben oder die Fehlersuche selbst in die Hand nehmen möchten, gebe ich Ihnen in diesem Artikel nützliche Tipps, wie Sie die Ursache des Problems finden können.
Ansatz
Ein Zitat aus der berühmten hippokratischen Schule der Medizin: "Übe zwei Dinge im Umgang mit Krankheiten: Entweder du hilfst dem Patienten oder du schadest ihm nicht."
Die Probleme in einer Produktionsnetzumgebung können manchmal nur vorübergehend sein. Es gibt Fälle, in denen das Testen mehr Störungen verursachen kann als das Problem selbst. Wenn ein vorübergehendes Problem behoben ist, wäre es besser, eine langfristige Überwachung zu planen und die Tests erst dann durchzuführen, wenn das Problem zum nächsten Mal auftaucht.
Ziel
Der Zweck der Fehlersuche und -behebung besteht darin, die Grundursache eines Problems zu ermitteln.
Mit Hilfe eines logischen Ansatzes können wir die folgenden Schritte zur Fehlerbehebung identifizieren:
- Erfolg definieren: einen spezifischen, erkennbaren und wünschenswerten Endpunkt definieren.
- Isolieren des Problems: Isolieren der Komponente, die den Erfolg verhindert.
- Identifizieren einer Lösung: Die Lösung verursacht keine weiteren Probleme, die Lösung überlebt einen Neustart.
- Lösung implementieren: Änderungskontrollprozesse befolgen, Wartungsfenster verwenden.
Informationen sammeln
Stellen Sie zusätzliche Fragen, zum Beispiel:
- "Seit wann ist dies der Fall?"
- "Gibt es Auswirkungen auf den Betrieb?"
- "Hat es jemals funktioniert?"
- "Wann hat es zuletzt wie gewünscht funktioniert?
- "Was hat sich geändert?"
- "Welche Schritte und Massnahmen zur Fehlerbehebung wurden bereits versucht?"
RSI und System-Logs
Die häufigsten Informationsquellen für die Fehlersuche sind rsi (request support information) und der Inhalt von /var/log. Nachfolgend ein Beispiel, wie Sie die Dateien finden können:
RSI
root@yoda> request support information | save /var/log/rsi-yy-mm-dd.txt
Logs
root@yoda>file archive compress source /var/log/* destination /var/tmp/yy-mm-dd_LOGRSI_DeviceName.tgz
sftp: get /var/tmp/yy-mm-dd_LOGRSI_DeviceName.tgz
Der Befehl " Request support information " liefert eine Liste der meisten Befehle, die zur Analyse des Gerätezustands erforderlich sind.
RSI
Im Folgenden werde ich mich auf die vom rsi gelieferten Infos konzentrieren und einige Beispiele für häufig auftretende Probleme beschreiben.
Software-Version
root@yoda> show version detail no-forwarding
Hostname: yoda
Model: srx240
Junos: 18.2R3.4
Wenn es sich beim gemeldeten Problem um ein aussergewöhnliches Verhalten handelt, besteht die Möglichkeit, dass dies durch einen Problembericht (PR) verursacht wird. Ein einfaches Überprüfen der Junos-Version und das Durchsuchen der bekannten PRs kann helfen, den RCA zu finden und Ihnen viel Zeit zu sparen.
Sie können eine PR-Suche nach Version und Schlüsselwörtern durchführen unter: https://prsearch.juniper.net
Beispiel
Der Kunde bemerkt einen starken Anstieg der Speichernutzung der RE1 (Backup-Routing-Engine) auf dem MX240-Router, der Junos 18.4R2.7 verwendet. In den Protokollen kann nichts Relevantes gefunden werden und es gibt keine aktuelle Konfigurationsänderung.
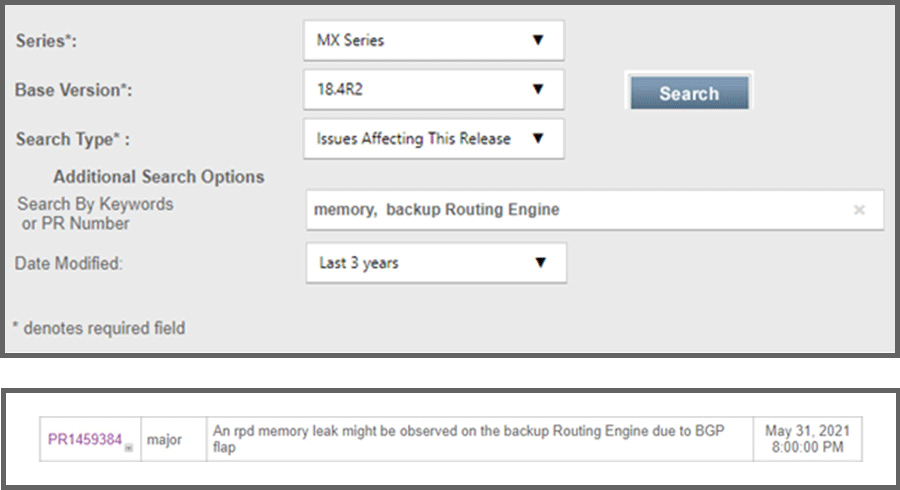
Mit Hilfe von Schlüsselwörtern in der PR-Suchfunktion kann PR1459384 als RCA identifiziert werden.
Die Lösung ist ein Software-Upgrade.
Core Files
Im Falle einer schwerwiegenden Fehlfunktion kann eine Core-Dump-Datei erstellt werden, welche die Programmumgebung in Form von Speicherzeigern, Anweisungen und Registerdaten enthält.
Beispiel
Der Kunde berichtet von einem spontanen Neustart seines Geräts. In der rsi sind Core-Dumps zu sehen:
root@yoda> show system core-dumps no-forwarding
-rw-rw—- 1 root wheel 4307560 Apr 21 2021 /var/tmp/pfed.core-tarball.0.tgz
-rw-r–r– 1 root wheel 1035087872 Apr 7 2021 /var/tmp/smgd.core.live.1
….
/var/tmp/pics/*core*: No such file or directory
/var/crash/kernel.*: No such file or directory
…
total files: 12
Followed by logs:
Apr 21 14:27:40.890 2021 Yoda_RE0 kernel: Dumping 2040 out of 49108 MB:..1%..11%..21%..31%..41%..51%..61%..71%..81%..91%
Apr 21 14:27:40.890 2021 Yoda_RE0 kernel: Dump complete
Apr 21 14:27:40.890 2021 Yoda_RE0 kernel: Automatic reboot in 15 seconds – press a key on the console to abort
Feb 18 14:27:40.890 2021 Yoda_RE0 kernel: Rebooting…
Wir können sehen, dass der Auslöser für den unerwünschten Neustart ein Kernel-Core war.
Ein Softwareentwickler, der einen Debugger und eine Version der ausführbaren Datei verwendet, die Debugsymbole enthält, kann die resultierende Kerndatei analysieren und die Abfolge der Ereignisse ermitteln, die zum Absturz geführt haben. Sobald diese Informationen bekannt sind, können Abhilfemassnahmen ergriffen werden.
Warnmeldungen
Wenn es Bedingungen gibt, die verhindern, dass das Gerät im Gehäuse oder die Systemsoftware normal funktioniert, ist es immer nützlich, die Warnmeldungen zu überprüfen.
Beispiel 1
root@yoda_RE0> show chassis alarms no-forwarding
1 alarms currently active
Alarm time Class Description
2021-06-18 13:33:28 UTC Major PEM 4 Not Powered
Gefolgt von:
user@yoda_RE0> show chassis power
…
PEM 4:
State: Present
Input: Absent
Dies deutet auf einen Hardwarefehler des PEMs hin, der die Erstellung einer RMA erfordert.
Beispiel 2
user@yoda> show chassis alarms
1 alarms currently active
Alarm time Class Description
2021-06-10 12:24:09 CEST Major FPC 2 Major Errors
Lösung: Wenn diese Warnmeldung auftritt, lassen sich die FPC-Fehler in der Regel durch erneutes Einsetzen der Karte beheben (physisch entfernen und wieder einsetzen).
Beispiel 3
user@yoda> show chassis alarms
2 alarms currently active
Alarm time Class Description
2021-04-27 09:02:06 CET Minor Loss of communication with Backup RE
2021-04-21 09:01:34 CET Minor Backup RE Active
Gefolgt von den Logs
Apr 04 08:14:17 CHASSISD_MASTER_LOG_MSG: – No response from the other routing engine for the last 360 seconds.
Apr 04 08:14:17 CHASSISD_MASTER_LOG_MSG: – No response from the other routing engine for the last 2 seconds.
Apr 04 08:14:17 CHASSISD_MASTER_LOG_MSG: – Keepalive timeout of 2 seconds expired. Assuming RE mastership.
In diesem Beispiel kommt es zu einem Wechsel der Masterschaft, weil Keepalives zwischen den beiden RE ausgelassen wurden. Um die RE wiederherzustellen, ist ein Reseat der nächste empfohlene Schritt. Bleibt der Reseat erfolglos, kann ein RMA erstellt werden.
Prozesse
user@yoda> show system processes extensive no-forwarding
last pid: 23839; load averages: 0.46, 0.59, 0.49 up 0+00:49:27 15:15:35
328 processes: 8 running, 272 sleeping, 1 zombie, 47 waiting
Mem: 2802M Active, 5196M Inact, 2346M Wired, 1572M Buf, 37G Free
Swap: 3072M Total, 3072M Free
Folgende Punkte könnten auf ein Problem hinweisen:
- Zu viele Zombie-Prozesse
- Verwendung von umfangreichem Swap-Speicher
- Nicht genügend verfügbarer Speicher
- Unerwartet hohe CPU-Auslastung für bestimmte Prozesse (ausser im Leerlauf)
Chassis Routing Engine
Überprüfung von Speicher-/CPU-Auslastung, Betriebszeit, Neustartgrund
Beispiel
Der Kunde meldet, dass einer seiner Switches unerwartet neu gebootet wurde. Es gibt keine nützlichen Protokolle, keinen Core-Dump und keine Warnmeldungen. Ein Blick auf die Prozesse zeigt eine hohe CPU-Auslastung.
Eine Überprüfung der Chassis-Routing-Engine zeigt, dass der Grund für den letzten Neustart folgender war: Router rebooted : 0x2000: hypervisor reboot.
Da eine hohe CPU-Auslastung festgestellt wurde, bevor die Probleme mit dem Switch begannen, könnte dies erklären, warum der interne KVM-Hypervisor unerwartet neu gestartet wurde.
Hinweis
Bei Routing Engines der MX-Serie kann der Grund für den Neustart auch über die Shell ermittelt werden, indem Sie den folgenden Shell-Befehl verwenden:
% sysctl hw.re.reboot_reason
Bit 0 wird gesetzt, wenn ein Neustart aufgrund eines Stromausfalls oder eines Stromzyklus' erfolgt.
Bit 1 wird gesetzt, wenn ein Neustart durch einen Hardware-Watchdog ausgelöst wird.
Bit 2 wird gesetzt, wenn ein Neustart durch die Reset-Taste ausgelöst wird.
Bit 3 wird gesetzt, wenn der Netzschalter gedrückt wird.
LOGS
Interpretation von Syslog-Meldungen
Bei Verwendung des Standard-Syslog-Formats besteht jeder in die Nachrichtendateien geschriebene Protokolleintrag aus den folgenden Feldern:
- Zeitstempel: Zeitpunkt der Protokollierung der Meldung
- Name: Der konfigurierte Systemname
- Prozessname oder PID: Name des Prozesses, der den Protokolleintrag erzeugt hat (oder die Prozess-ID, wenn ein Name nicht verfügbar ist).
- Meldungscode: Ein Code, der die allgemeine Art und den Zweck der Meldungen angibt, Beispiel: CHASSISD_FRU_EVENT
- Meldungstext: zusätzliche Informationen zum Meldungscode
Eine vollständige Beschreibung der verschiedenen Meldungscodes und ihrer Bedeutung finden Sie in der Dokumentation System Log Messages Reference:
https://www.juniper.net/documentation/partners/ibm/junos11.4-oemlitedocs/syslog-messages.pdf
Um die Details eines beliebigen Protokolltyps zu ermitteln, verwenden Sie den Befehl:
user@yoda>help syslog log-name
Beispiel für "Strange Logs":
- Jul 5 11:29:53 Yoda fpc0 brcm_pw_get_egr_stats: Egr Pkt Counter fetch failed.
→ Der PFE versucht, bestimmte Statistiken zu erhalten. Diese Meldungen sind harmlos und informativ. Syslog-Filter können angewendet werden, um diese Protokolle zu filtern. Das Problem wurde mit PR1491819 behoben.
- Jul 10 07:19:08 2020 Yoda fpc0 BRCM_SALM:brcm_salm_periodic_clear_pending(),153: Failed to delete Pending entres forunit = 0, modid = 0, port = 27, err code =
→ Übereinstimmung PR1475005
- Oct 22 15:21:05 Yoda xntpd[9279]: kernel time sync enabled 2001
- Oct 22 16:48:06 Yoda eventd: sendto: No route to hostOct 22 16:48:06 QFX51-4.ZH4 eventd[16886]: SYSTEM_ABNORMAL_SHUTDOWN: System abnormally shut
→ Übereinstimmung PR1459384
- re0 chassisd[17080]: CHASSISD_I2CS_READBACK_ERROR: Readback error from I2C slave for FPC 5 ([0x17, 0x21] →0x0)
→ Die auf dem Gerät registrierten Protokolle werden in der Regel angezeigt, wenn der FPC defekt ist, so dass das Chassis nicht in der Lage ist, den FPC-Status über die i2c-Verbindungen zwischen dem CB und dem FPC zu lesen, oder wenn es ein Kommunikationsproblem gibt, das durch die Midplane verursacht wird.
Versuchen Sie, den FPC wieder einzubauen. Wenn dies nicht funktioniert, kann eine RMA erstellt werden.
May 5 06:34:12 2020 Yoda fpc0
- BRCM_SALM:brcm_salm_periodic_clear_pending(),126: Pending entres konnte nicht gelöscht werden für unit = 0, tgid = 2, err code = -9
→ Übereinstimmung PR1371092
- Jun 24 09:13:29 lab-re0 /kernel: rt_pfe_veto: Too many delayed route/nexthop unrefs. Op 2 err 55, rtsm_id 5:-1, msg type 2
Jun 24 09:13:29 lab-re0 /kernel: rt_pfe_veto: Memory usage of M_RTNEXTHOP type = (0) Max size possible for M_RTNEXTHOP type = (16711550976) Current delayed unref = (40151), Current unique delayed unref = (40000), Max delayed unref on
→ Check: KB36114
Das rt_pfe_veto bedeutet, dass der FPC überlastet ist und eine "Veto"-Meldung an den RE sendet, damit dieser ihm keine zu bearbeitenden Routen schickt.
- pio_read_u64() failed and jspec_pio_read_u256 failed ()
→ Check: KB24641
Dieser Fehler kommt von der Speicherintegritätsprüfung, die regelmässig vom LU-Treiber durchgeführt wird. Wenn beim Lesen ein Fehler in der Prüfung auftritt, versucht der LU-Treiber, den Fehler zu reparieren, indem er die Daten in seiner Schattenkopie in denselben IDMEM/GUMEM-Speicherplatz schreibt. Wenn der Fehler behoben ist, werden die nachfolgenden Speicherprüfungen erfolgreich sein, da die Fehlermeldung nicht mehr angezeigt wird.


